|
My research is focused on 3D and Generative AI. In particular, I aim to find efficient methods for reconstructing, generating, and understanding the dynamic 3D world. To this end, I use tools from computer vision, machine learning, and computer graphics. I am always seeking excellent students and postdocs. If you are interested, please contact me! As an ELLIS Scholar, I also welcome applications through the ELLIS PhD and Postdoc Program. |

|
|
|
|
Roni Itkin, Noam Issachar, Yehonatan Keypur, Xingyu Chen, Anpei Chen, Sagie Benaim. ECCV, 2026. project page / arXiv / code GlobalSplat learns a compact set of global scene tokens to encode multi-view input and resolve cross-view correspondences before decoding 3D geometry, achieving competitive novel-view synthesis with as few as 16K Gaussians and inference under 78ms. |
|

|
Gal Fiebelman, Hadar Averbuch-Elor, Sagie Benaim. ECCV, 2026. We tackle the task of long multi-view video generation: generating temporally coherent video from multiple viewpoints simultaneously, at arbitrary lengths and viewpoint counts. MV-Forcing bridges the gap between temporal and view-wise autoregression using a 4D geometric prior, enabling geometrically consistent generation of dynamic scenes. |

|
Noam Issachar*, Guy Yariv*, Sagie Benaim, Yossi Adi, Dani Lischinski, Raanan Fattal. ICML, 2026. project page / arXiv / code DyPE lets pre-trained diffusion transformers generate ultra-high-res images (16M+ px) without retraining or extra cost, by matching positional encoding extrapolation to diffusion's shift from low-freq structures to high-freq details. |
|
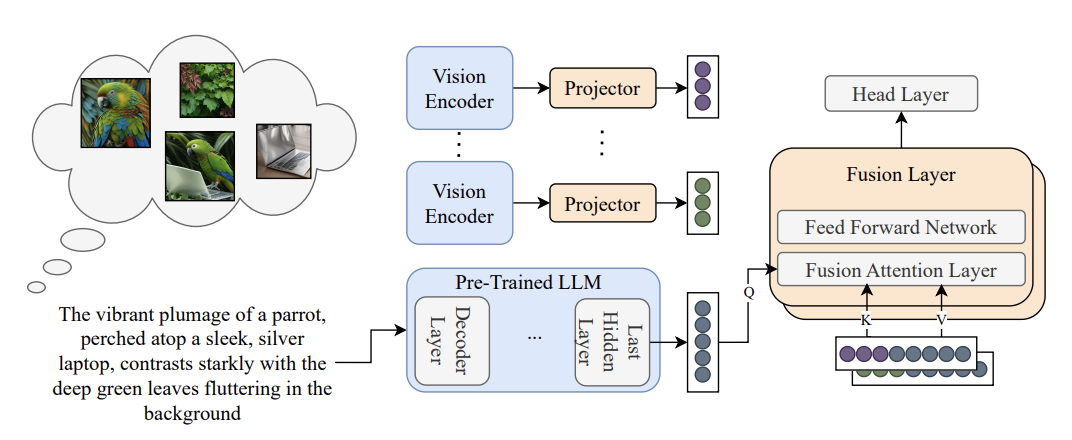
Guy Yariv, Idan Schwartz, Yossi Adi*, Sagie Benaim*. ACL, 2026. (Oral Presentation) project page / arXiv / code We improve large language models' visual commonsense by generating multiple images from text prompts and integrating them into decision-making via late fusion, boosting performance on visual commonsense reasoning and NLP tasks. |

|
Gal Fiebelman, Hadar Averbuch-Elor, Sagie Benaim. CVPR, 2026. project page / arXiv We present a novel hybrid framework that combines Gaussian-particle representations for incorporating physically-based global weather effects into static 3D Gaussian Splatting scenes, correctly handling the interactions of dynamic elements with the static scene. |
|
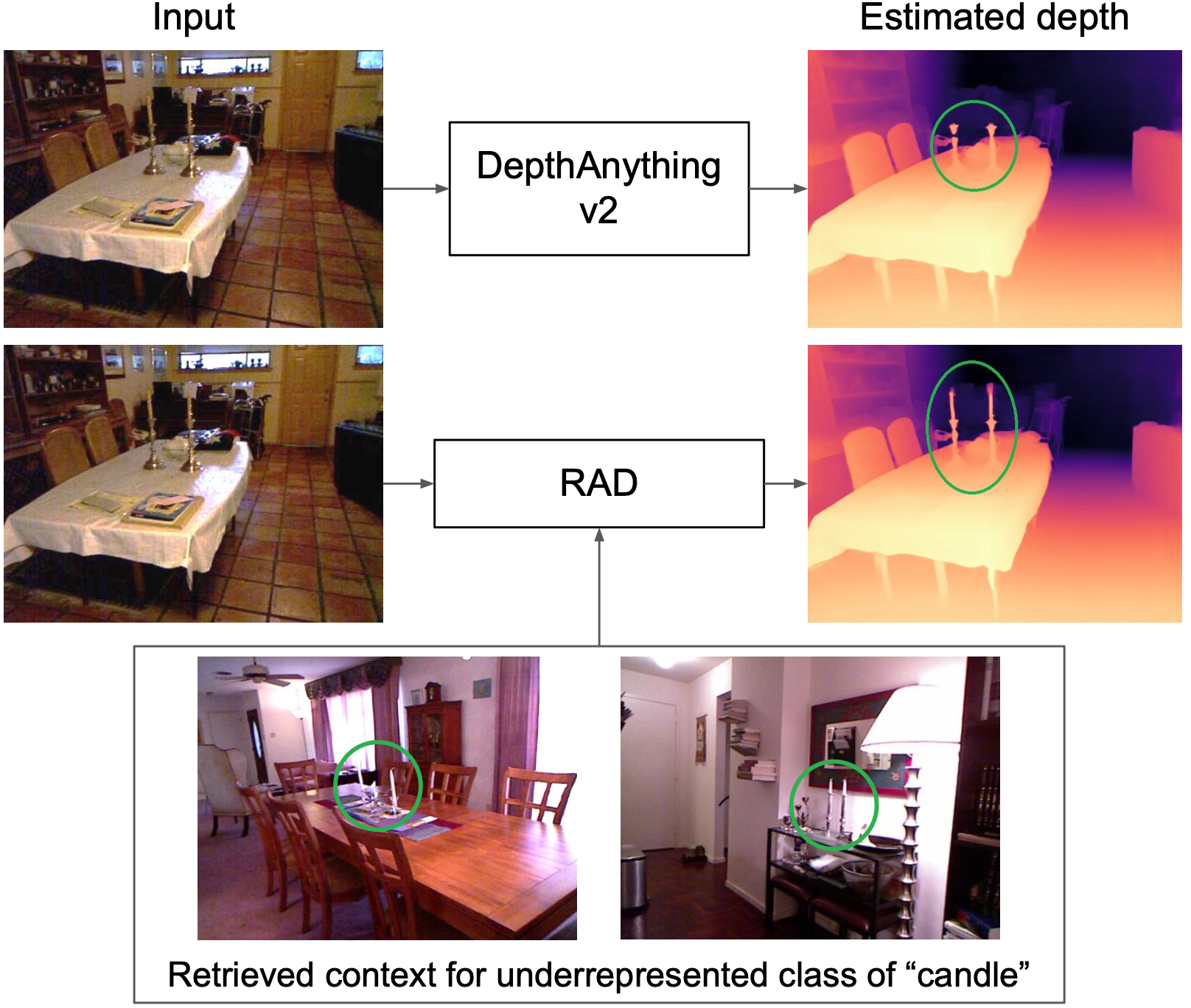
Michael Baltaxe, Dan Levi, Sagie Benaim. CVPR (Findings), 2026. project page / arXiv We propose RAD, a retrieval-augmented framework that approximates the benefits of multi-view stereo by utilizing retrieved neighbors as structural geometric proxies to improve monocular metric depth estimation for underrepresented classes in complex scenes. |
|
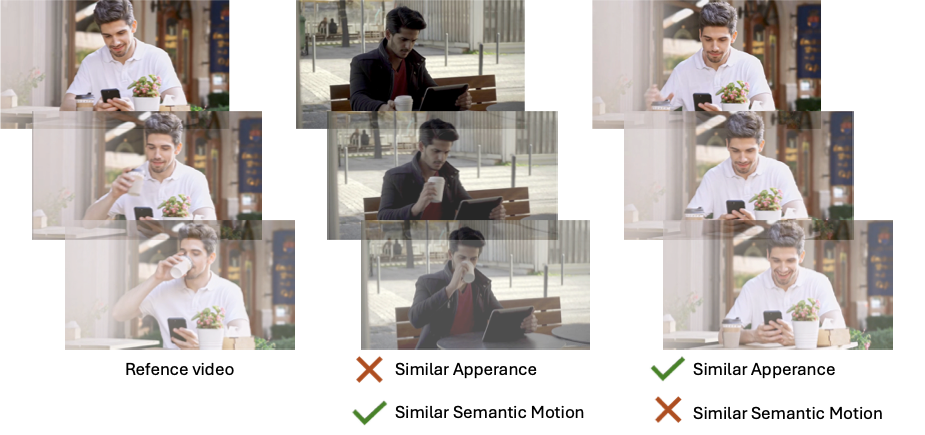
Saar Huberman, Kfir Goldberg, Or Patashnik, Sagie Benaim, Ron Mokady. CVPR (Findings), 2026. code / arXiv We propose SemanticMoments, a simple, training-free method that computes temporal statistics over features from pre-trained semantic models to retrieve videos based on semantic motion, addressing the bias of existing approaches that overly rely on static appearance. |
|
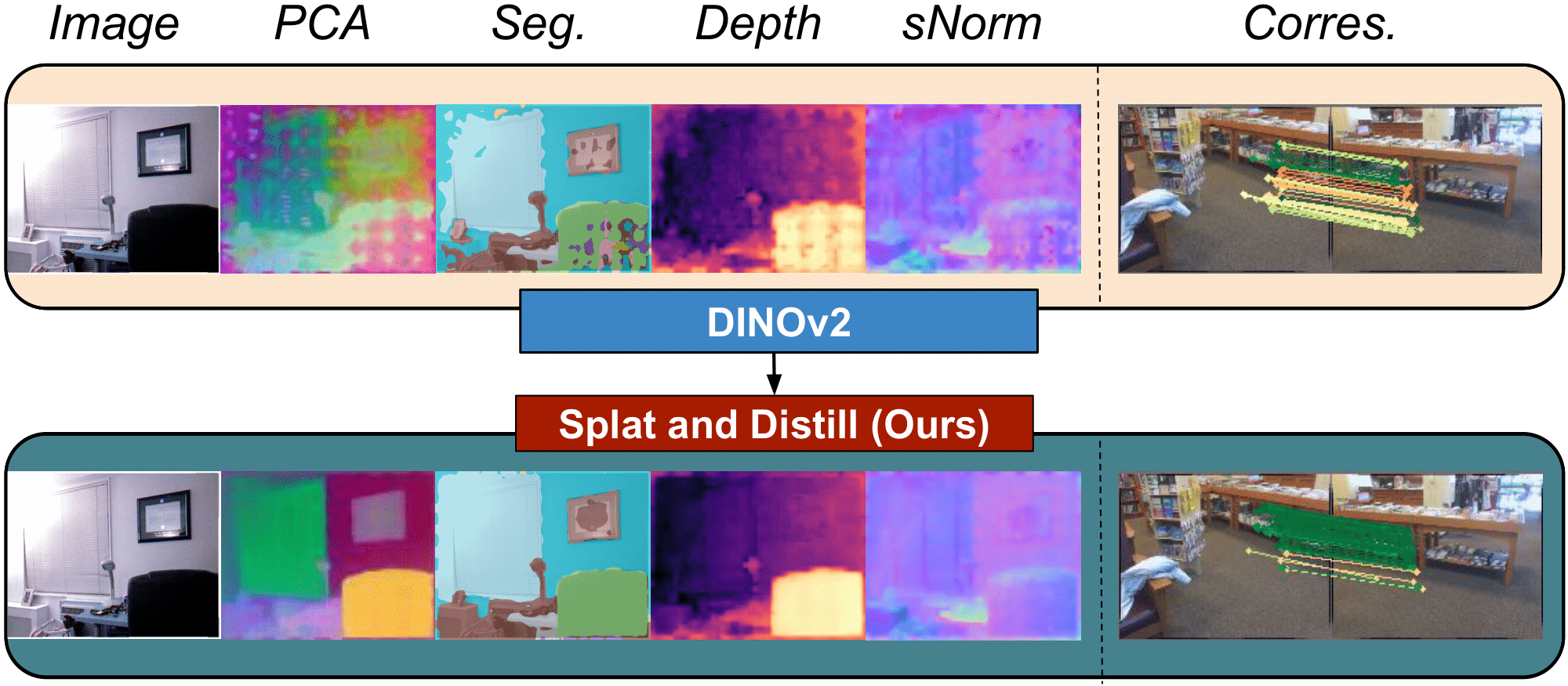
David Shavin, Sagie Benaim. ICLR, 2026. project page / arXiv / code We introduce a framework that instills robust 3D awareness into 2D Vision Foundation Models (VFMs) by augmenting the teacher model with a fast, feed-forward 3D reconstruction pipeline. This enables the distillation of geometrically grounded knowledge, significantly improving performance on downstream tasks such as depth estimation and semantic segmentation. |

|
Yoel Levy, David Shavin, Itai Lang, Sagie Benaim. 3DV, 2026. arXiv We learn 3D features using multiple disentangled feature fields that capture view-dependent and view-independent components. This enables a range of semantic and structural understanding and editing capabilities. |

|
Shai Krakovsky, Gal Fiebelman, Sagie Benaim, Hadar A. Elor. SIGGRAPH Asia, 2025. arXiv / project page / code /
We introduce Lang3D-XL, a method for efficiently distilling language features into large-scale, in-the-wild 3D Gaussian scenes. |
|
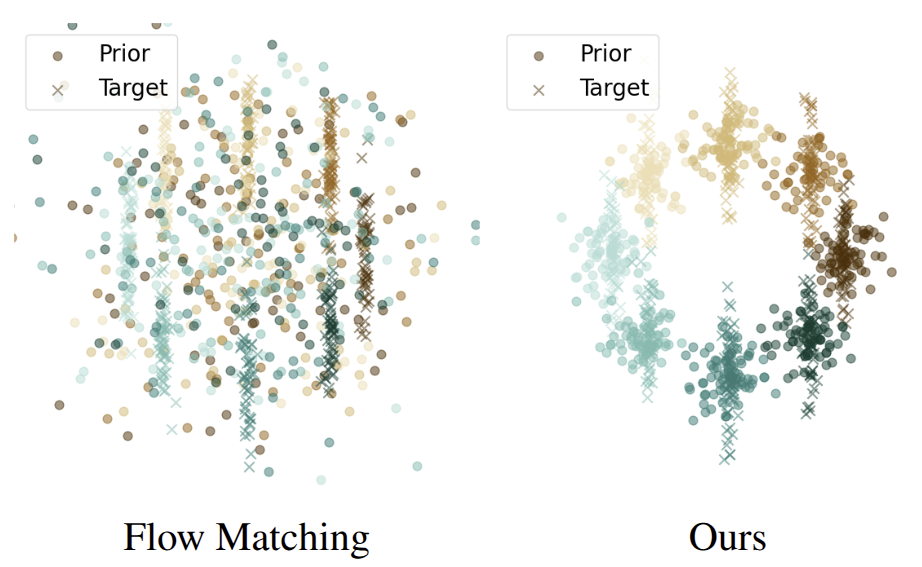
Noam Isaachar, Mohammad Salama, Raanan Fattal, Sagie Benaim. TMLR, 2025. (J2C Certification) arXiv
We tap into a non-utilized property of conditional flow-based models: the ability to design a non-trivial prior distribution. Given an input condition, such as a text prompt, we first map it to a point lying in data space. We then map samples from a parametric distribution centered around this point to the conditional target distribution. This significantly improves training times and generation efficiency. |

|
Guy Yariv, Yuval Kirstain, Amit Zohar, Shelly Sheynin, Yaniv Taigman, Yossi Adi, Sagie Benaim, Adam Polyak. CVPR, 2025. project page / arXiv We propose Through-The-Mask, a two-stage framework for Image-to-Video generation that uses mask-based motion trajectories to enhance object-specific motion accuracy and consistency, achieving state-of-the-art results, particularly in multi-object scenarios. |

|
Isaac Labe, Noam Issachar, Itai Lang, Sagie Benaim. ECCV, 2024. project page / arXiv / code We distill 2D semantic features to dynamic 3D Gaussian Splatting scenes, allowing for semantic segmentation of dynamic objects in 3D. |

|
Sebastian Loeschcke, Dan Wang, Christian Leth-Espensen, Serge Belongie, Michael J. Kastoryano, Sagie Benaim. ICML, 2024. project page / arXiv / code We introduce 'PuTT', a novel method for learning a coarse-to-fine tensor train representation of visual data, effective for 2D/3D fitting and novel view synthesis, even with noisy or missing data. |
|
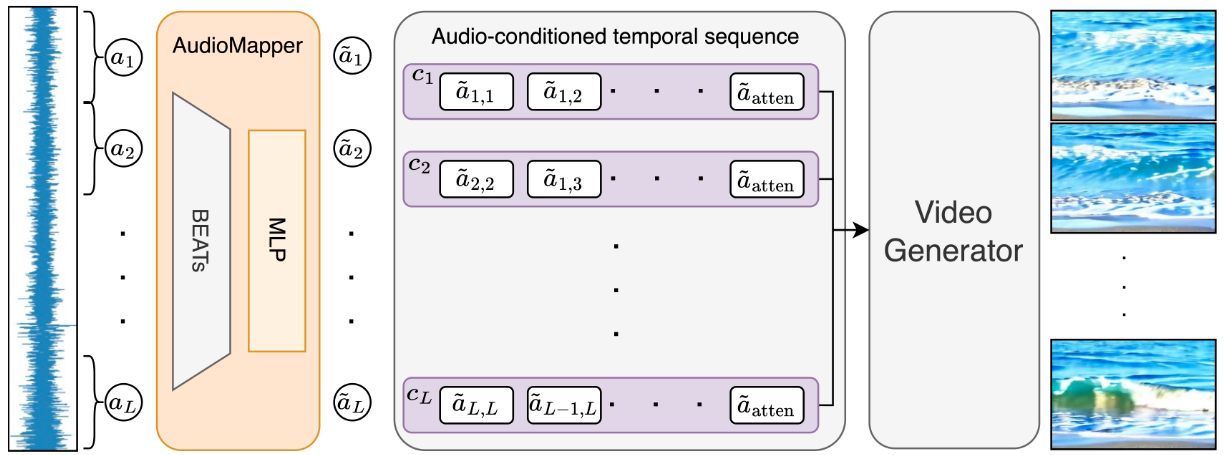
Guy Yariv, Itai Gat, Sagie Benaim, Lior Wolf, Idan Schwartz, Yossi Adi. AAAI, 2024. Also in the Controllable Video Generation (CVG) workshop, ICML 2024. project page / arXiv / code We consider the task of generating diverse and realistic videos guided by natural audio samples from a wide variety of semantic classes. The proposed method is based on a lightweight adaptor network, which learns to map the audio-based representation to the input representation expected by a pretrained text-to-video generation model. |
 
|
Sagie Benaim, Frederik Warburg, Peter Ebert Christensen, Serge Belongie WACV, 2024. project page / arXiv We propose a framework for disentangling a 3D scene into a forground and background volumetric representations and show a variety of downstream applications involving 3D manipulation. |

|
Peter Ebert Christensen, Vésteinn Snæbjarnarson, Andrea Dittadi, Serge Belongie, Sagie Benaim WACV, 2024. (Oral Presentation) project page / arXiv We propose a framework for generation of photorealistic images that can fool a classifier using automatic semantic manipulations. |
|
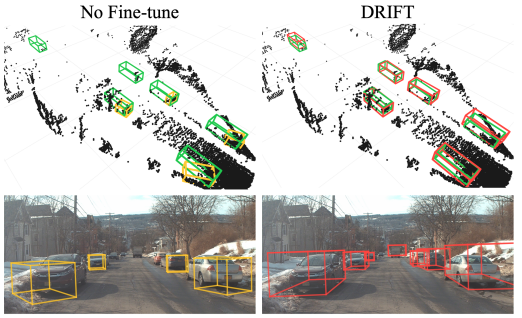
Katie Z Luo, Zhenzhen Liu, Xiangyu Chen, Yurong You, Sagie Benaim, Cheng Perng Phoo, Mark Campbell, Wen Sun, Bharath Hariharan, Kilian Q Weinberger. NeurIPS, 2023. arXiv We propose to adapt similar RL-based methods to Reinforcement Learning from Human Feedback (RLHF) for the task of unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. |
|
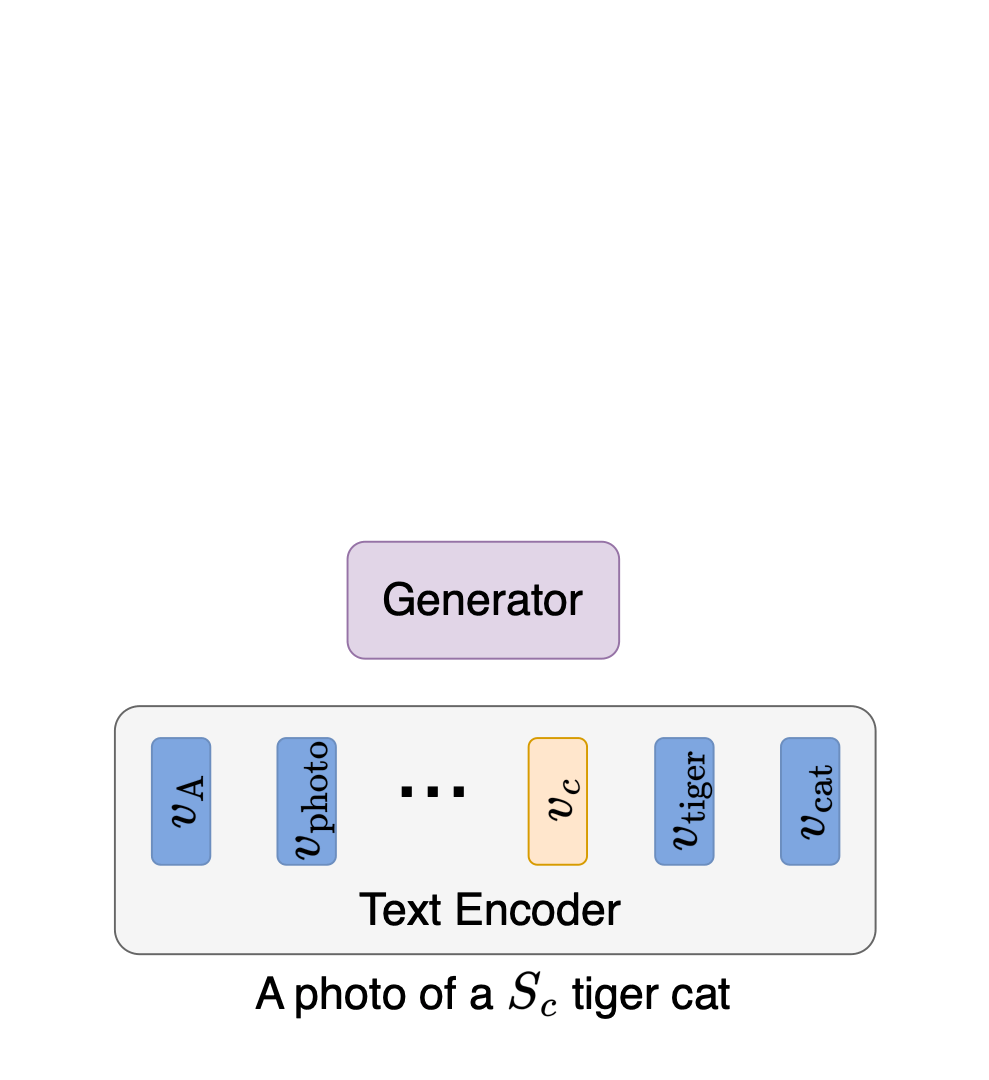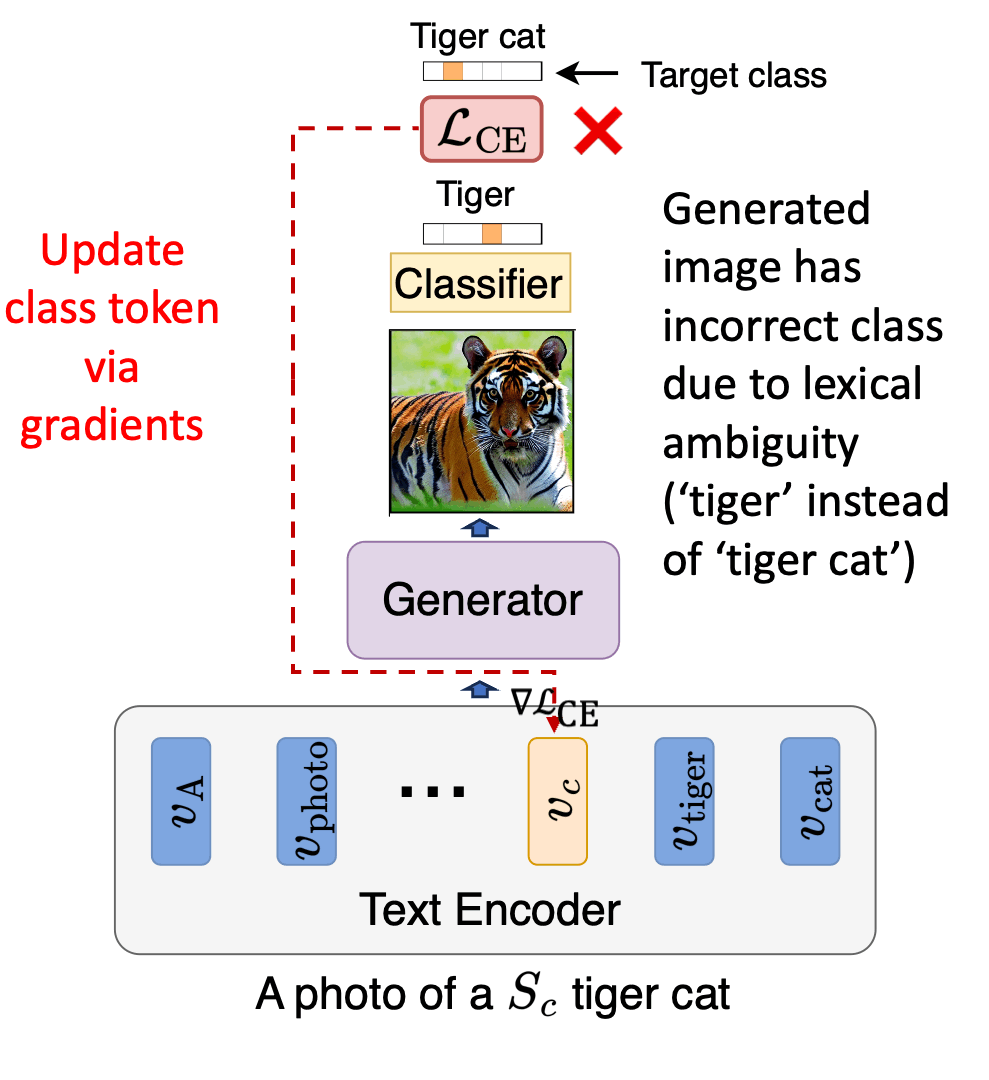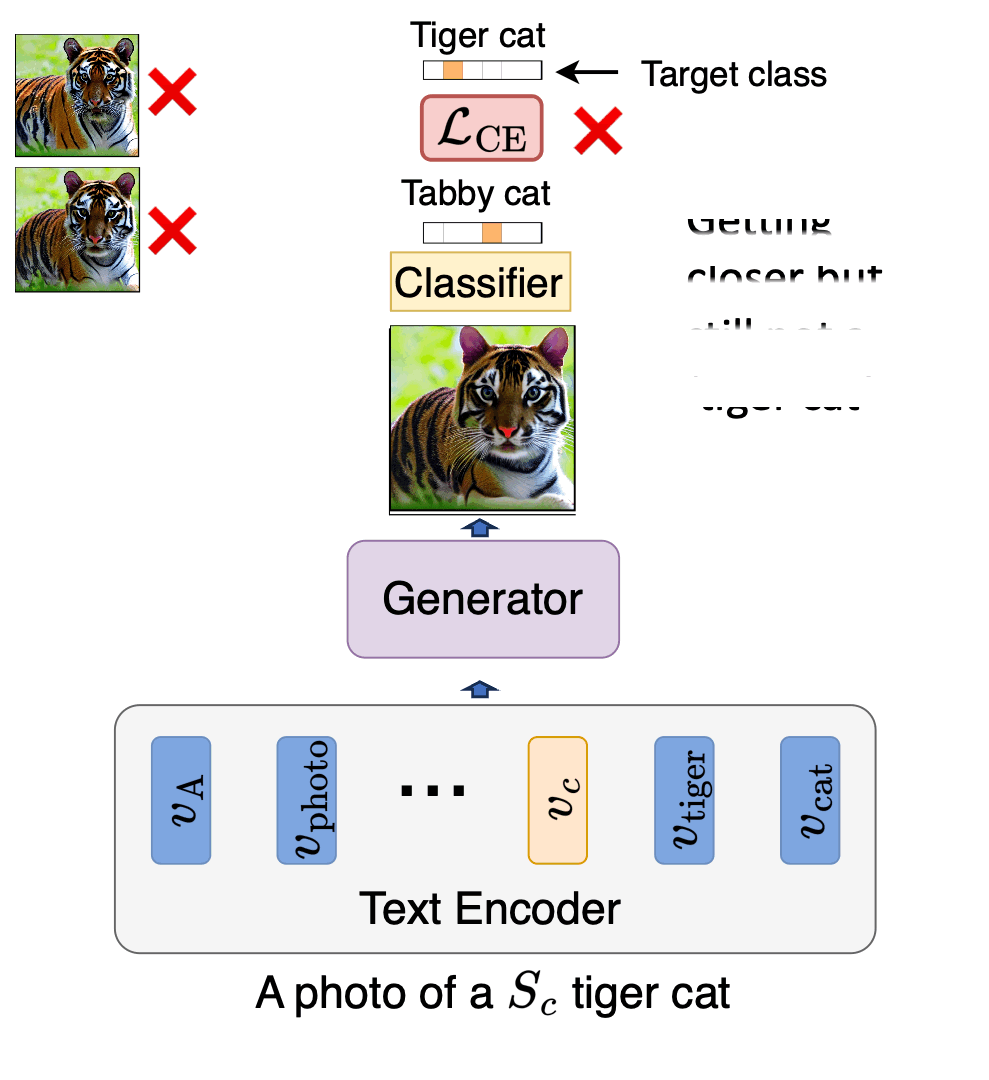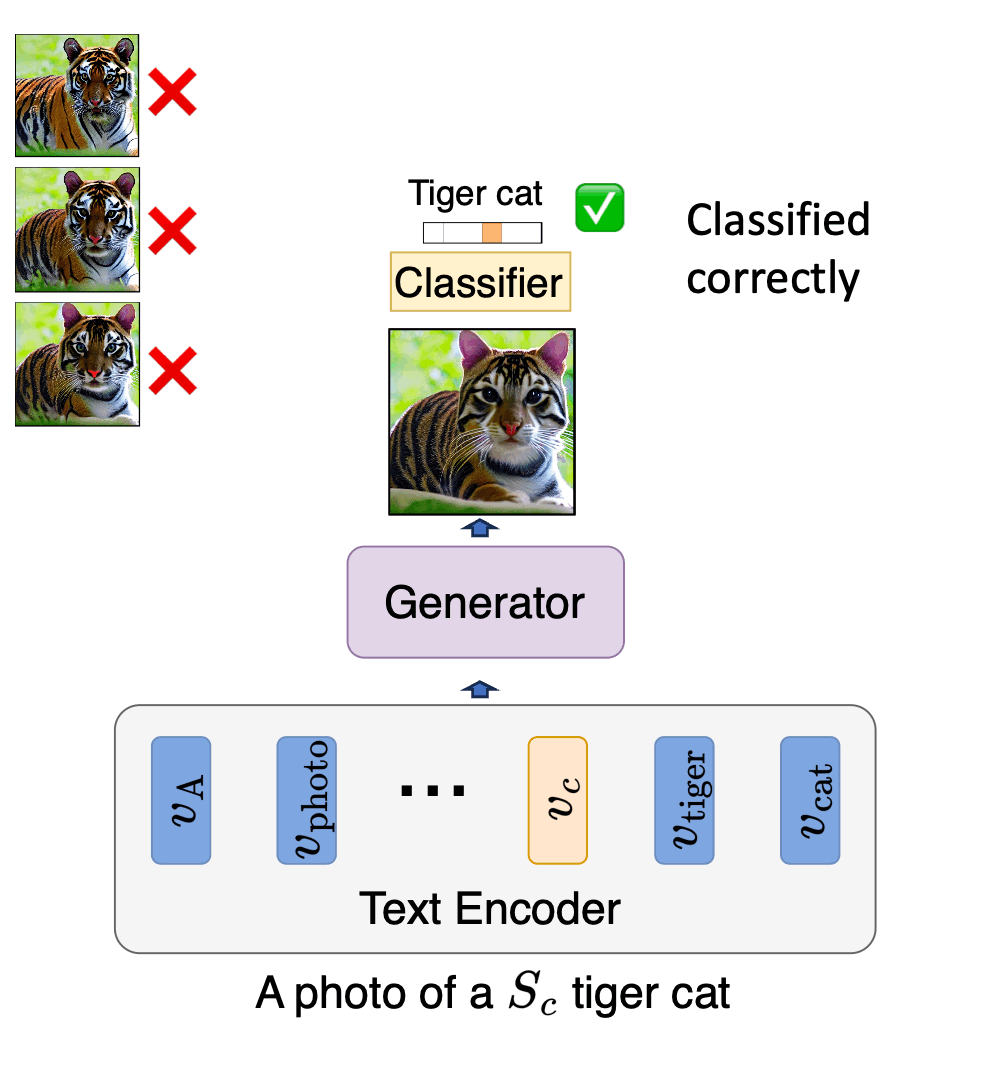
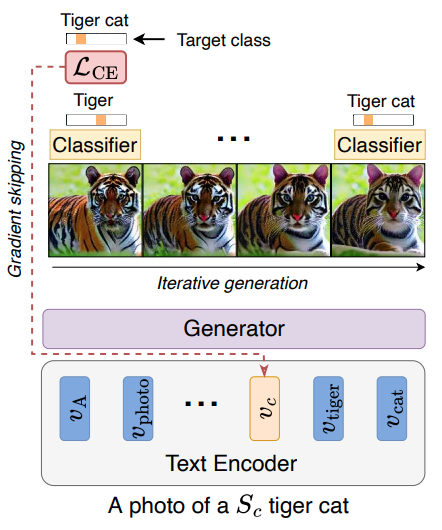
Idan Schwartz*, Vésteinn Snæbjarnarson*, Hila Chefer, Ryan Cotterell, Serge Belongie, Lior Wolf, Sagie Benaim. *Equal contribution. ICCV, 2023. project page / arXiv / code We propose a non-invasive fine-tuning technique fro Text-to-Image Diffusion Models that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. |

|
Guandao Yang*, Sagie Benaim*, Varun Jampani, Kyle Genova, Jonathan T. Barron, Thomas Funkhouser, Bharath Hariharan, Serge Belongie. *Equal contribution. NeurIPS, 2022. arXiv We propose a new class of neural fields called basis-encoded polynomial neural fields (PNFs). The key advantage of a PNF is that it can represent a signal as a composition of a number of manipulable and interpretable components without losing the merits of neural fields representation. |

|
Hila Chefer, Sagie Benaim, Roni Paiss, Lior Wolf ECCV, 2022. arXiv / code / 5 minute summary A new style (essense) transfer method that incoporates higher level abstractions then textures and colors. TargetCLIP introduces a blending operator that combines the powerful StyleGAN2 generator with a semantic network CLIP to achieve a more natural blending than with each model separately. |
 
|
Sebastian Loeschcke, Serge Belongie, Sagie Benaim ECCV Workshop on AI for Creative Video Editing and Understanding, 2022. (Best Paper Award) arXiv / project page A method for stylizing video objects in an intuitive and semantic manner following a user-specified text prompt. |

|
Oscar Michel*, Roi Bar-On*, Richard Liu*, Sagie Benaim, Rana Hanocka. CVPR, 2022. (Oral Presentation) project page / arXiv / code Text2Mesh produces color and geometric details over a variety of source meshes, driven by a target text prompt. Our stylization results coherently blend unique and ostensibly unrelated combinations of text, capturing both global semantics and part-aware attributes. |

|
Ron Mokady, Rotem Tzaban, Sagie Benaim, Amit Bermano, Daniel Cohen-Or Computer Graphics Forum, 2022. project page / arXiv / code We introduce JOKR - a JOint Keypoint Representation that captures the motion common to both the source and target videos, without requiring any object prior or data collection. This geometry-driven representation allows for unsupervised motion retargeting in a variery of challenging situations as well as for further intuitive control, such as temporal coherence and manual editing. |

|
Lior Ben Moshe, Sagie Benaim, Lior Wolf ICIP, 2022. arXiv FewGAN is a generative model for generating novel, high-quality and diverse images whose patch distribution lies in the joint patch distribution of a small number of N training samples. |
|
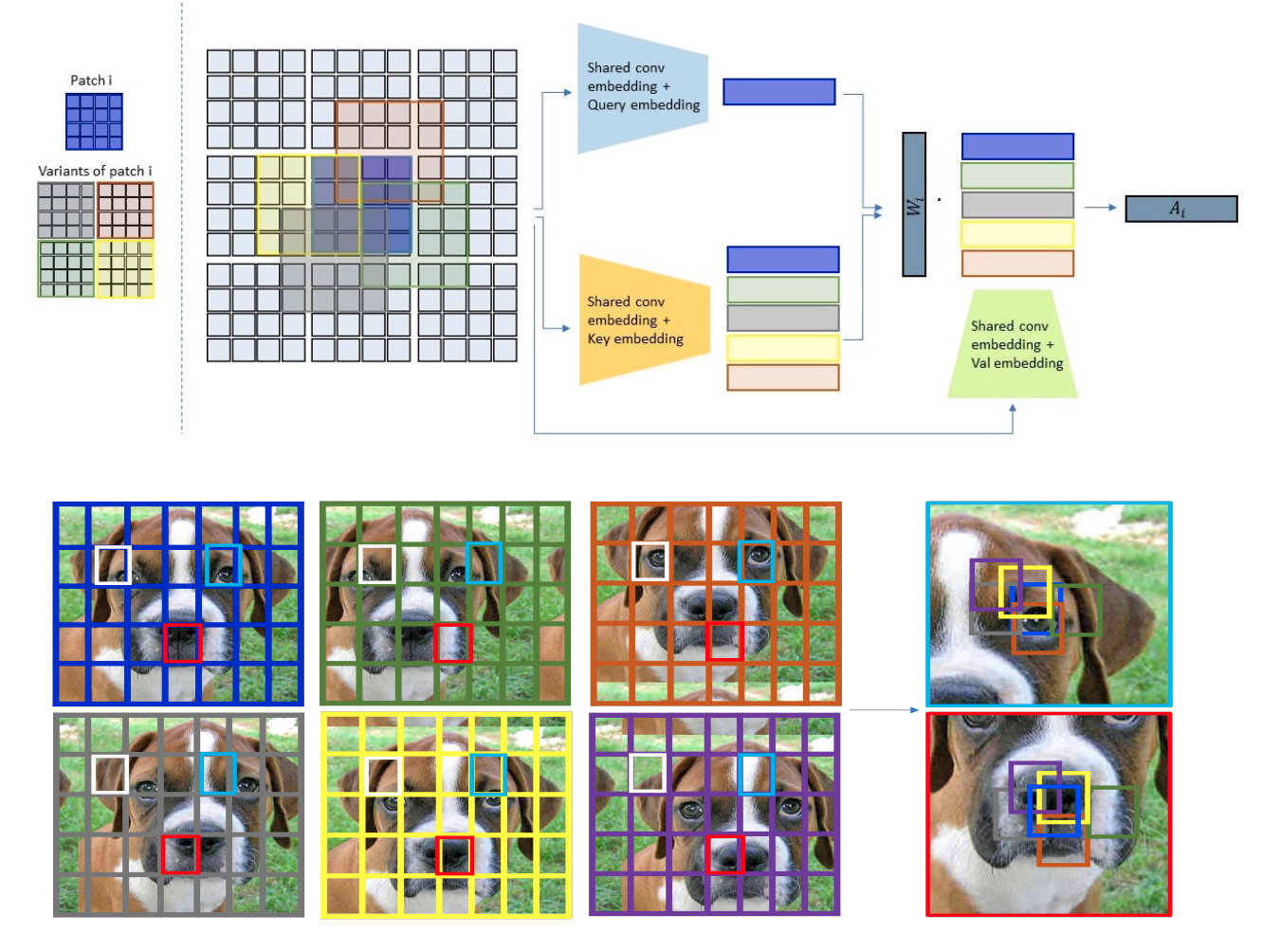
Shelly Sheynin, Sagie Benaim, Adam Polyak, Lior Wolf arXiv, 2021. arXiv / code A new image transformer architecture which first applies a local attention over patches and their local shifts, resulting in virtually located local patches, which are not bound to a single, specific location. Subsequently, these virtually located patches are used in a global attention layer. |

|
Shelly Sheynin*, Sagie Benaim*, Lior Wolf. *Equal Contribution. ICCV, 2021. project page / arXiv / code We consider the setting of few-shot anomaly detection in images, where only a few images are given at training. We devise a hierarchical generative model that captures the multi-scale patch distribution of each training image. We further enhance the representation of our model by using image transformations and optimize scale-specific patch-discriminators to distinguish between real and fake patches of the image, as well as between different transformations applied to those patches. |

|
Oren Nuriel, Sagie Benaim, Lior Wolf CVPR, 2021. arXiv / code A simple architectural change which forces the network to reduce its bias to global image statistics. Using AdaIN, we swap global statistics of samples within a batch, stocastically, with some probability p. This results in significant improvements in multiple settings including domain adaptation, domain generalization, robustness and image classification. |

|
Noam Gat, Sagie Benaim, Lior Wolf ICIP, 2021. arXiv / code StyleGAN can be used to upscale a low resolution thumbnail image of a person, to a higher resolution image. However, it often changes the person’s identity, or produces biased solutions, such as Caucasian faces. We present a method to upscale an image that preserves the person's identity and other attributes. |
|
Tomer Galanti, Sagie Benaim, Lior Wolf Journal of Machine Learning Research (JMLR), 2021. arXiv We develop theoretical foundations for the success of unsupervised cross-domain mapping algorithms, in mapping between two domains that share common characteristics, with a particular emphasis on the clear ambiguity in such mappings. |
|
Yaniv Beniv, Tomer Galanti, Sagie Benaim, Lior Wolf International Journal of Computer Vision (IJCV), 2020. arXiv Two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fréchet Inception Distance (FID). |

|
Sagie Benaim*, Ron Mokday*, Amit Bermano, Daniel Cohen-Or, Lior Wolf. *Equal contribution. Computer Graphics Forum, 2020. Also in the Deep Internal Learning workshop, ECCV 2020. project page / arXiv / code / video We explore the capabilities of neural networks to understand image structure given only a single pair of images, A and B. We seek to generate images that are structurally aligned: that is, to generate an image that keeps the appearance and style of B, but has a structural arrangement that corresponds to A. Our method can be used for: guided image synthesis, style and texture transfer, text translation as well as video translation. |
 
|
Shir Gur*, Sagie Benaim*, Lior Wolf. *Equal contribution. NeurIPS, 2020. Also in the Deep Internal Learning workshop, ECCV 2020. project page / arXiv / code / video
We consider the task of generating diverse and novel videos from a single video sample. We introduce a novel patch-based variational autoencoder (VAE) which allows for a much greater diversity in generation. Using this tool, a new hierarchical video generation scheme is constructed resulting in diverse and high quality videos.
|
|
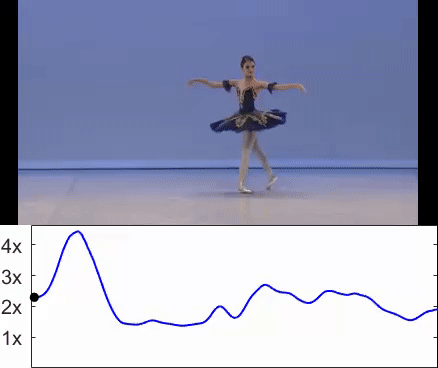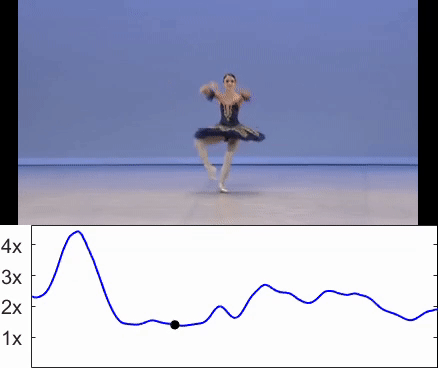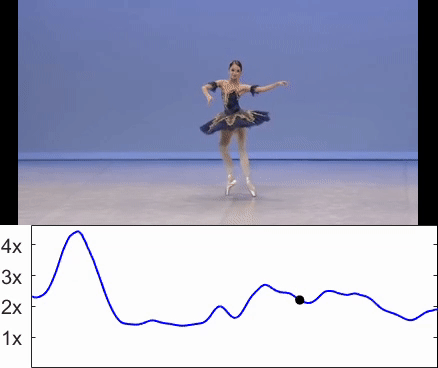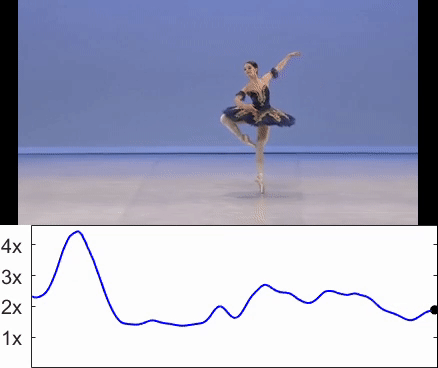
Sagie Benaim, Ariel Ephrat, Oran Lang, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Michal Irani, Tali Dekel CVPR, 2020. (Oral Presentation) project page / arXiv / video We train a network called SpeedNet to to automatically predict the "speediness" of moving objects in videos - whether they move faster, at, or slower than their "natural" speed. SpeedNet is trained in a self-supervised manner and can be used to generate time-varying, adaptive video speedups as well as to boost the performance of self-supervised action recognition and video retrieval. |

|
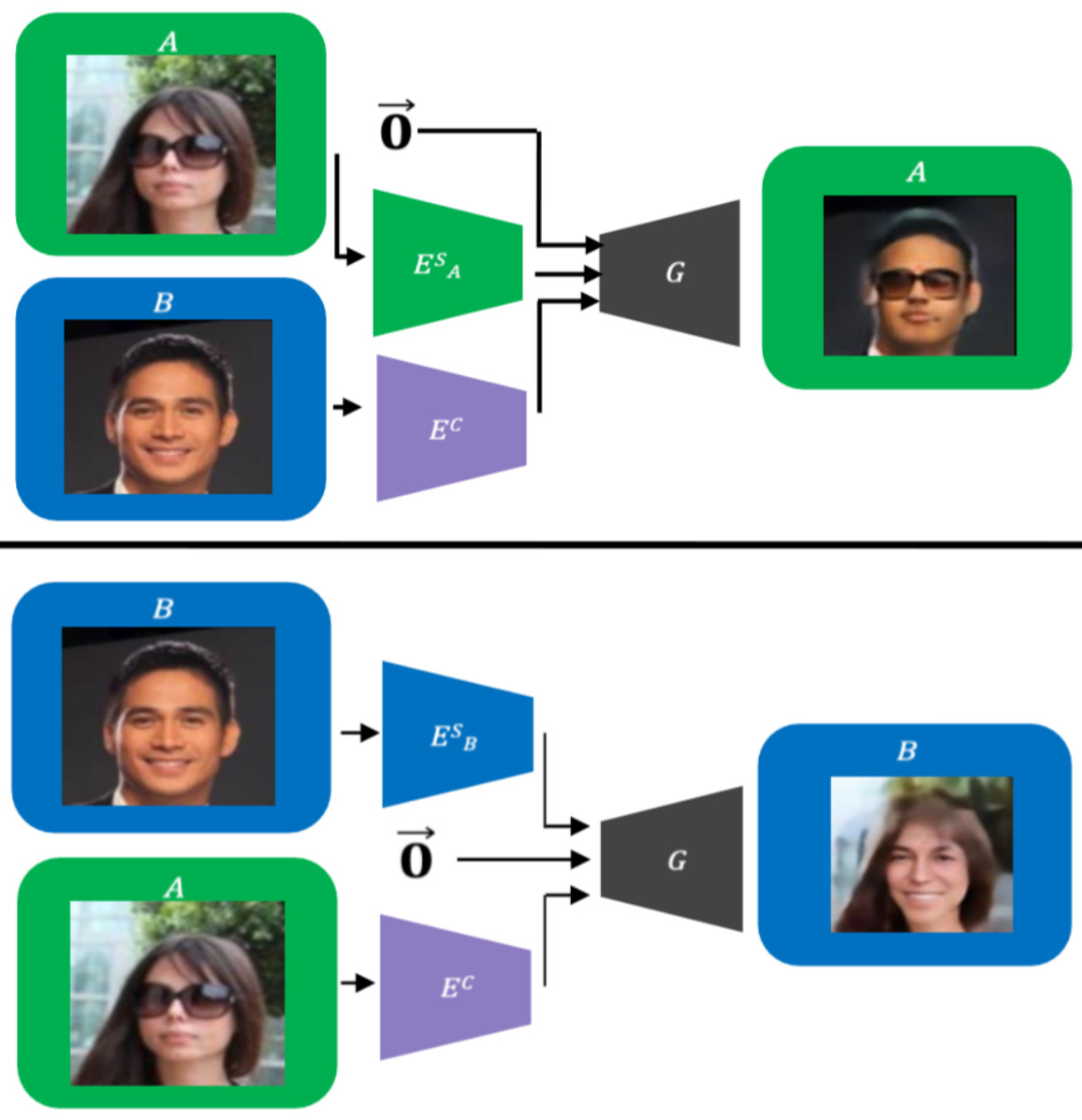
Ron Mokday, Sagie Benaim, Amit Bermano, Lior Wolf ICLR, 2020. arXiv / code / video We consider the problem of translating, in an unsupervised manner, between two domains where one contains some additional information compared to the other. To do so, we disentangle the common and separate parts of these domains and, through the generation of a mask, focuses the attention of the underlying network to the desired augmentation, without wastefully reconstructing the entire target. |
|
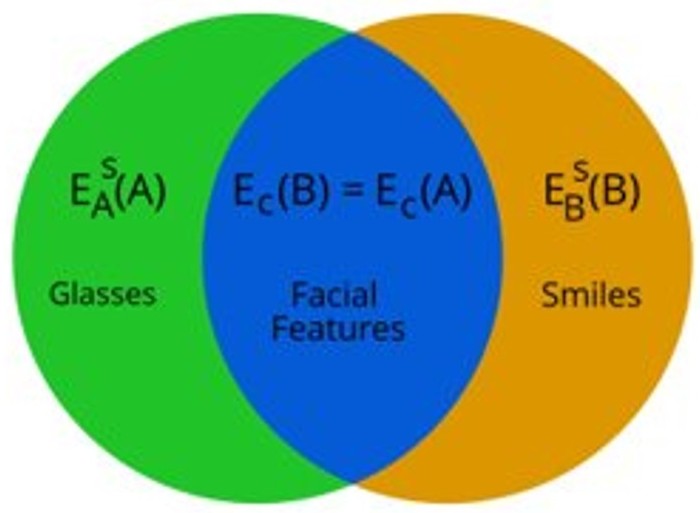
Sagie Benaim, Michael Khaitov, Tomer Galanti, Lior Wolf ICCV, 2019. arXiv / code
We present a method for recovering the shared content between two visual domains as well as the content that is unique to each domain. This allows us to remove content specific content of the first domain and add content specific to the second domain. We can also generate form the intersection of the two domains and their union, despite having no such samples during training.
|
|
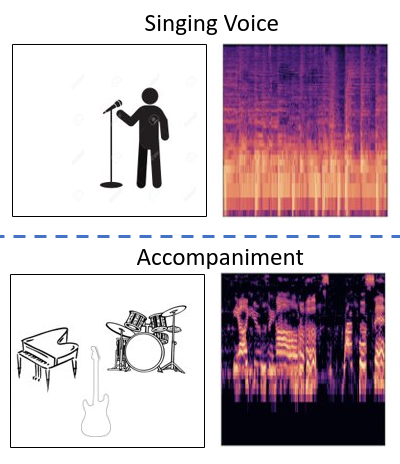
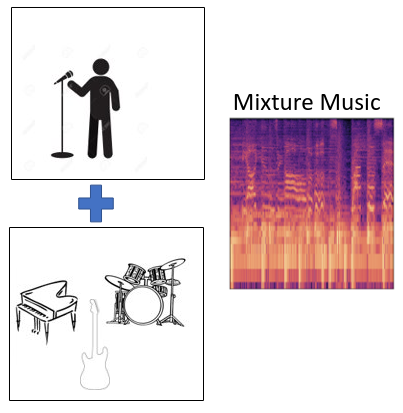
Michael Michelashvili, Sagie Benaim, Lior Wolf ICASSP, 2019. arXiv / code / samples
We study the problem of semi-supervised singing voice separation, in which the training data contains a set of samples of mixed music (singing and instrumental) and an unmatched set of instrumental music. Our results indicate that we are on a par with or better than fully supervised methods, which are also provided with training samples of unmixed singing voices, and are better than other recent semi-supervised methods.
|

|
Ori Press, Tomer Galanti, Sagie Benaim, Lior Wolf ICLR, 2019. arXiv / code
We study the problem of learning to map, in an unsupervised way, between domains A and B, such that the samples b in B, contain all the information that
exists in samples a in A, and some additional information.
|
|
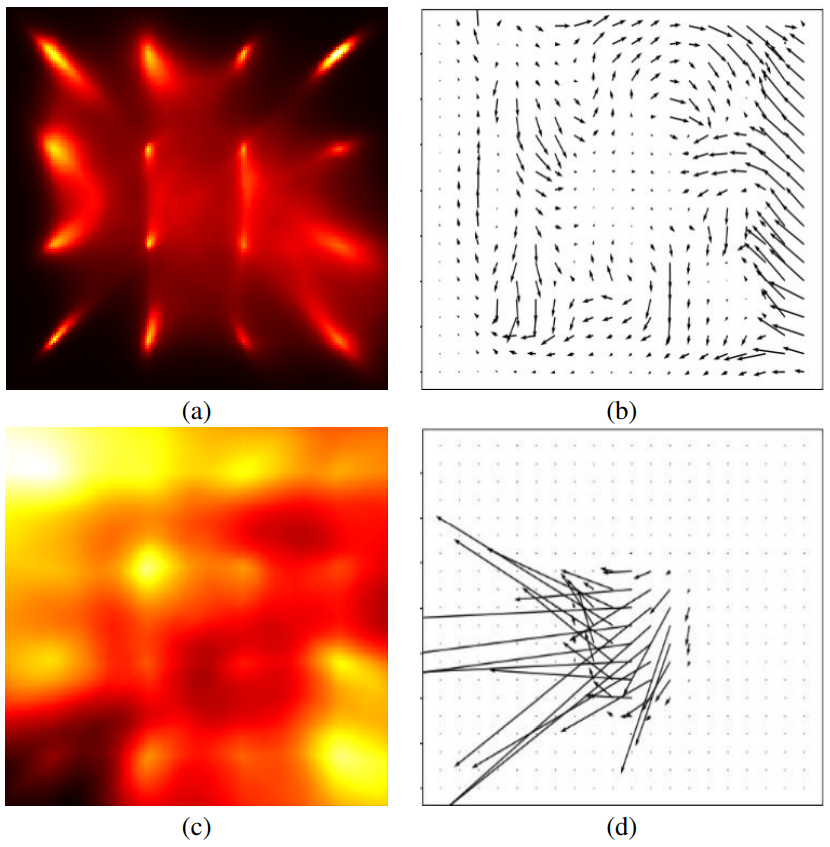
Lior Wolf, Sagie Benaim, Tomer Galanti ICLR, 2019. arXiv
We study a new form of unsupervised learning, whose input is a set
of unlabeled points that are assumed to be local maxima of an unknown value
function v in an unknown subset of the vector space. Two functions are learned:
(i) a set indicator c, which is a binary classifier, and (ii) a comparator function
h that given two nearby samples, predicts which sample has the higher value of
the unknown function v.
|

|
Sagie Benaim, Lior Wolf NeurIPS, 2018. arXiv / code
Given a single image x from domain A and a set of images from domain B, we consider the task of
generating the analogous of x in B.
|
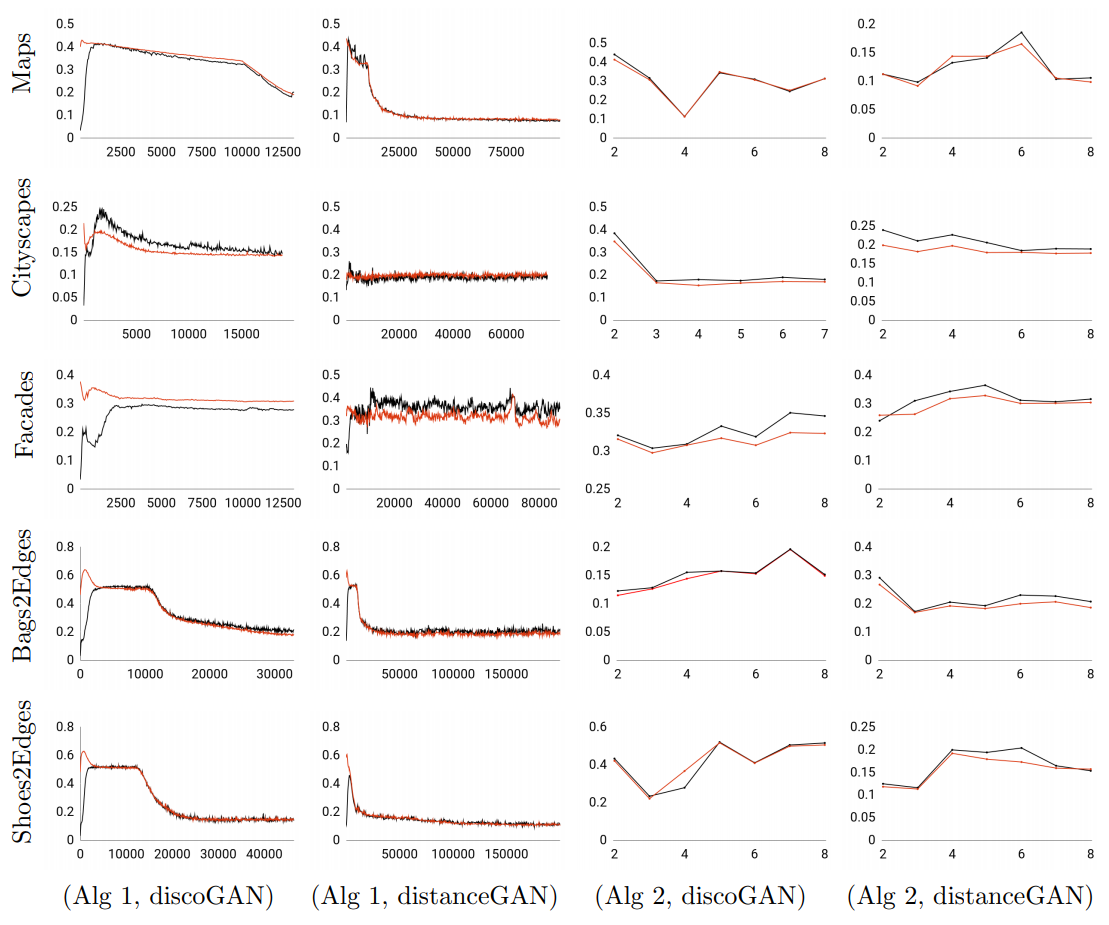
|
Sagie Benaim*, Tomer Galanti*, Lior Wolf. *Equal contribution. ECCV, 2018. arXiv / code
While in supervised learning, the validation error is an unbiased estimator of the
generalization (test) error and complexity-based generalization bounds are abundant, no such bounds exist for learning a mapping in an unsupervised way.
We propose a novel bound for predicting the success of unsupervised cross domain
mapping methods.
|
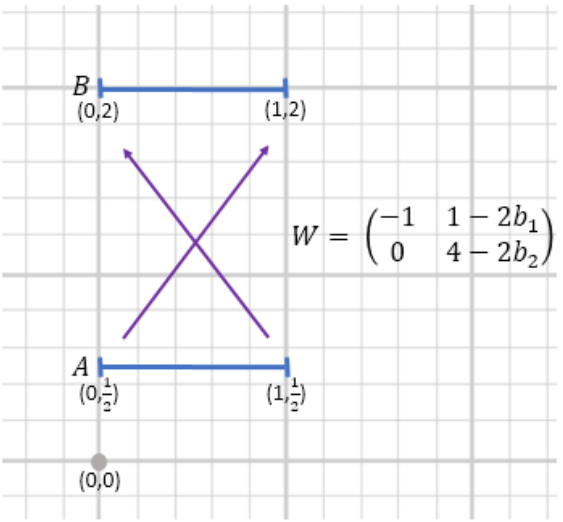 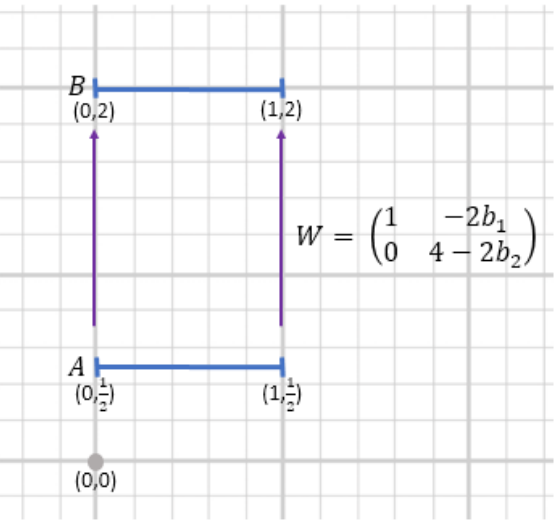
|
Tomer Galanti, Sagie Benaim, Lior Wolf ICLR, 2018. arXiv
We discuss the feasibility of the unsupervised cross domain generation problem. In the typical setting this problem is ill posed: it seems possible to build infinitely many alternative mappings from every target mapping. We identify the abstract notion of aligning two domains and show that only a minimal architecture and a standard GAN loss is required to learn such mappings, without the need for a cycle loss.
|
 
|
Sagie Benaim, Lior Wolf NIPS, 2017. (Spotlight) arXiv / code
We consider the problem of mapping, in an unsupervised manner, between two visual domains in a one sided fashion.
This is done by learning an equivariant mapping that maintains the distance between a pair of samples.
|
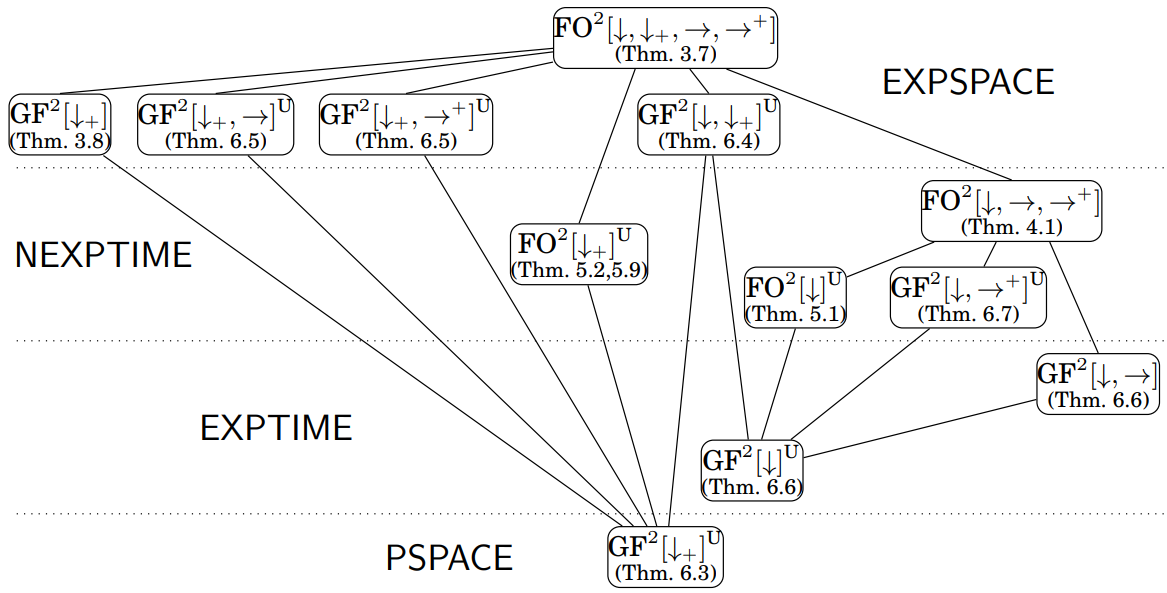
|
Sagie Benaim, Michael Benedikt, Witold Charatonik, Emanuel Kieroński, Rastislav Lenhardt, Filip Mazowiecki, James Worrell ICALP, 2013 and ACM Transaction of Computational Logic, Volume 17, 2016 (MSc Thesis). This work contains a comprehensive analysis of the complexity the two-variable fragment of first-order logic FO2 on trees. |

|
|
|
Retrieval-Augmented 3D Vision: Analysis and Generation in the Long Tail,
Israel Machine Vision Conference (IMVC), Expo Tel Aviv, June 2026.
3D-Aware Latent Tokens for 3D Reconstruction, Generation, and Understanding, CVPR 2026 Area Chairs Workshop, Denver, June 2026. Distilling Foundation Models for a Semantic Reconstruction of the 3D World, Technion Pixel Club, November 2025; Amazon Research, Tel Aviv, October 2025. Towards a Controllable Generation of the Multimodal World, ELLIS, AI4media, and AIDA Symposium on Large Language and Foundation Models, Amsterdam, 2023. Towards a Controllable Generation of the 3D World, Hebrew University of Jerusalem, Tel Aviv University, Weizmann Institute of Science, Bar Ilan University, Technion Institute, Haifa University, Meta AI Research Tel Aviv, 2022-2024. Text2Mesh: Text-Driven Stylization for Meshes, Israel Computer Vision Day 2021, Pre-CVPR Day, University of Copenhagen, 2022. Semantic Manipulation of Visual Content, Pioneer Center of AI Colloquium, hosted by Aarhus University and Technion CDS Seminar, 2021. Structure-Aware Manipulation of Images and Videos, 2021. Facebook AI Research (London), Stanford SVL Meeting, Google Research (Tel Aviv), Nvidia Research (San Francisco) , Technion CDS Seminar, Tel Aviv Visual Computing Seminar. Manipulating Structure in Images and Videos., Nvidia Research (Tel Aviv), Berkeley, 2021. On disentangled and few shot visual generation and understanding, Google Viscam Seminar, 2020. Learning the Speediness in Videos and Generating Novel Videos From a Single Sample, Hebrew University Vision Seminar, Technion ML Seminar, 2020. SpeedNet: Learning the Speediness in Videos, Viz.ai, 2020. Visual Analogies: The role of disentanglement and learning from few example, Hebrew University Vision Seminar, 2020. Domain Intersection and Domain Difference, 2020. Amazon Research (Tel Aviv), , ICCVi, 2019. Generative Adversarial Networks for Image to Image Translation, IMVC, 2019. Video. New Capabilities in Unsupervised Image to Image Translation, Bar Ilan ML Seminar, 2019. One-Shot Unsupervised Cross Domain Translation, Technion CDS Seminar, 2019. Introduction to Generative Adversarial Networks, Elbit, 2018. Generative Adversarial Networks for Image to Image Translation, Nexar, 2018. One-Sided Unsupervised Domain Mapping, Hebrew University Vision Seminar, Weizmann Institute Vision Seminar, Technion Pixel Club, 2018. |
This page design is based on a template by Jon Barron.